
در این مقاله، به زبان ساده بررسی کرده ایم که مهمترین تفاوت یادگیری ماشینی و یادگیری عمیق چیست؟ و اینکه چرا گاهی ML کلاسیک کافی است و کی باید سراغ Deep Learning بروید؛ البته این مبحث را همراه با مثالهای واقعی، مقایسه دقیق و راهنمای انتخاب بهترین روش برای پروژهتان شرح داده ایم. چرا که در سال های اخیر و با گسترش سریع هوش مصنوعی، اصطلاحات «یادگیری ماشینی» (Machine Learning) و «یادگیری عمیق» (Deep Learning) بسیار پرکاربرد شده اند. اما بسیاری از افراد، به ویژه متخصصان تازه کار و حتی بعضی افراد با تجربهی متوسط، این دو مفهوم را به دلیل شباهت ظاهری یکی می پندارند. در حالیکه یادگیری عمیق، زیرمجموعهای از یادگیری ماشینی است.
در واقع، مهمترین تفاوت های یادگیری ماشینی و یادگیری عمیق که دقیقا تعیین کننده موفقیت پروژه های هوش مصنوعی هستند، در معماری مدل، فرآیند آموزش، حجم دادهی مورد نیاز، توان محاسباتی، روش استخراج ویژگی و نوع مسائلی است که هر کدام به بهترین شکل حل می کنند.
این تفاوت یادگیری ماشینی و یادگیری عمیق وقتی اهمیت پیدا می کند که قرار است برای یک پروژه واقعی مثلا در حوزه ی تحلیل داده، پردازش تصویر، پردازش زبان طبیعی، اتوماسیون صنعتی یا هر کاربرد دیگری، تصمیم گیری کنید. چرا که انتخاب نادرست بین این دو رویکرد می تواند زمان توسعه را طولانی تر کند، هزینه های سخت افزاری و عملیاتی را به شدت افزایش دهد و حتی دقت و عملکرد نهایی سیستم را پایین بیاورد.

مقایسه یادگیری ماشینی و یادگیری عمیق
برای مقایسه کلیدی این دو رویکرد، باید بگوییم؛ یادگیری ماشینی به مجموعه الگوریتم هایی گفته می شود که با استفاده از روش های آماری و ریاضی، مدل هایی برای پیش بینی، طبقه بندی یا کشف الگو می سازند. در بیشتر موارد، این الگوریتم ها به ویژگی هایی وابسته اند که توسط انسان (مهندس ویژگی یا متخصص دامنه) به صورت دستی استخراج و آماده سازی شده است.
در مقابل، یادگیری عمیق شاخه ای تخصصی تر است که بر پایه ی شبکه های عصبی چندلایه (عمیق) کار می کند. این شبکه ها قادرند به صورت کاملا خودکار و بدون نیاز به مهندسی دستی ویژگی، الگوهای پیچیده و سلسله مراتبی را مستقیما از داده های خام استخراج کنند.
به همین دلیل، وقتی داده ها حجیم و غیرساخت یافته هستند و الگوها بسیار پیچیده، یادگیری عمیق معمولا عملکرد به مراتب بهتری ارائه می دهد؛ اما در عوض به داده ی بسیار بیشتر و توان محاسباتی سنگین (معمولا GPU یا TPU) نیاز دارد. در مقابل، الگوریتم های کلاسیک یادگیری ماشینی با داده های کمتر، سخت افزار معمولی و زمان آموزش کوتاه تر هم می توانند نتایج قابل قبولی بدهند.
درک دقیق تفاوت یادگیری ماشینی و یادگیری عمیق دیگر فقط یک موضوع آکادمیک نیست. تیم های فنی و شرکت ها هر روز با این تصمیم عملی روبه رو هستند که آیا برای پیش بینی رفتار کاربران یا تشخیص تقلب مالی، مدل های سنتی یادگیری ماشینی کافی است؟ یا برای تشخیص اشیا در ویدیو، ترجمه همزمان گفتار یا تشخیص پزشکی از روی تصویر، حتما باید به سراغ یادگیری عمیق برویم؟ پاسخ درست به این سوال مستقیما روی زمان تحویل پروژه، بودجه و کیفیت خروجی تاثیر می گذارد.
اصلی ترین تفاوت یادگیری ماشینی و یادگیری عمیق
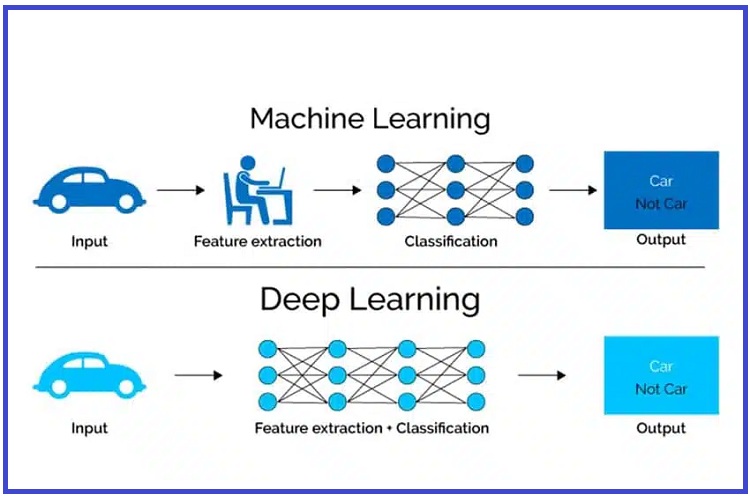
اصلی ترین تفاوت های بین یادگیری ماشینی و یادگیری عمیق را می توان در سه حوزهی کلیدی شامل مدلها، کاربرد و نحوهی برخورد با داده ها به سه صورت زیر بررسی کرد:
- تفاوت در ساختار معماری مدل ها
- تفاوت در کاربرد و نوع مسئله
- تفاوت در میزان داده و توان محاسباتی
در یادگیری ماشینی کلاسیک، بیشتر الگوریتم ها (مانند رگرسیون لجستیک، درخت تصمیم، جنگل تصادفی یا ماشین بردار پشتیبان SVM) ساختاری مشخص، نسبتا ساده و قابل تحلیل دارند. این مدل ها دادهی خام را دریافت می کنند، اما برای رسیدن به عملکرد مطلوب به شدت به ویژگی های مهندسی شده وابسته اند.
به عبارت دیگر، پیش از آغاز فرآیند آموزش، متخصص داده یا مهندس ویژگی باید به صورت دستی مهمترین ویژگی ها را شناسایی، استخراج و آماده سازی کند. در بسیاری از پروژه های واقعی، کیفیت و هوشمندی این ویژگی های دستی تعیین کننده ی اصلی موفقیت یا شکست مدل است.
در مقابل، یادگیری عمیق این مرحله ی پرزحمت را کاملا حذف می کند و شبکه های عصبی چندلایه فرآیند استخراج ویژگی را به طور کامل درون خود مدل ادغام کرده اند. به این ترتیب، دادهی خام وارد شبکه می شود و طی عبور از لایه های متوالی، ابتدا الگوهای بسیار ساده و سپس به تدریج مفاهیم پیچیده تر و انتزاعی تر شناسایی و ساخته می شوند.
همین ویژگی باعث شده یادگیری عمیق (در حوزه هایی مانند پردازش تصویر، تشخیص و تولید گفتار، پردازش زبان طبیعی و هر کاربرد دیگری که روابط پنهان و چندسطحی در داده وجود دارد)، عملکردی به مراتب برتر داشته باشد؛ جایی که طراحی دستی ویژگی ها یا بسیار دشوار است یا عملا غیرممکن به نظر می رسد.
یکی دیگر از جنبه های کلیدی این تفاوت اصلی، مقیاس داده است؛ مدل های کلاسیک یادگیری ماشینی معمولا با مجموعه داده های کوچک تا متوسط هم به نتایج قابل قبولی می رسند، چون پیچیدگی و تعداد پارامترهایشان محدود است. اما شبکه های عمیق به دلیل داشتن میلیون ها و گاهی میلیاردها پارامتر، تنها در حضور داده های حجیم و متنوع می توانند به پتانسیل واقعی خود برسند. در صورت کمبود داده، این مدل ها به سرعت دچار بیش برازش (overfitting) می شوند و توانایی تعمیم پذیری خود را از دست می دهند.
توان محاسباتی نیز عامل تعیین کننده ی دیگری است؛ آموزش یک مدل کلاسیک اغلب روی یک لپ تاپ یا سرور معمولی به راحتی انجام می شود و برخی الگوریتم ها حتی در کسری از ثانیه آموزش می بینند. در مقابل، آموزش مناسب یک شبکه عمیق معمولا نیازمند پردازنده های گرافیکی قدرتمند (GPU) و گاهی چندین کارت گرافیک به صورت موازی است. این نیاز به سخت افزار تخصصی مستقیما هزینهی زیرساخت و زمان توسعه را افزایش می دهد و باید پیش از تصمیم گیری جدی گرفته شود.
در نهایت با توجه به این تفاوت های اصلی، انتخاب بین یادگیری ماشینی و یادگیری عمیق کاملا به ماهیت مسئله بستگی دارد که در جدول زیر مشاهده می کنید:
| شرایط پروژه | رویکرد پیشنهادی |
|---|---|
| داده محدود باشد، ویژگیها به راحتی قابل استخراج باشند و تفسیرپذیری همراه با سرعت آموزش و اجرا اهمیت داشته باشد | یادگیری ماشینی کلاسیک |
| داده پیچیده، حجیم و غیرساختیافته باشد و هدف دستیابی به بالاترین دقت ممکن باشد | یادگیری عمیق |
این جدول به شما برای تصمیم گیری درست درباره پروژه هایتان کمک میکند. البته در ادامه توضیحات بیشتری ارائه کرده ایم تا موضوع تفاوت میان یادگیری ماشین و یادگیری عمیق کاملا روشن شود.
۱- تفاوت در ساختار معماری مدل ها
مهمترین عامل تمایز یادگیری ماشینی و یادگیری عمیق، دقیقا در ساختار و معماری مدل ها نهفته است.
در یادگیری ماشینی کلاسیک، معماری مدل ها معمولا ساده، ثابت و کاملا قابل درک است:
- رگرسیون ها روابط خطی یا غیرخطی محدود را مدل می کنند
- ماشین بردار پشتیبان (SVM) به دنبال یافتن بهترین مرز تصمیم در فضای ویژگی است
- درخت های تصمیم و جنگل تصادفی داده ها را با تقسیم بندی های گام به گام و بر اساس قوانین اگر-آنگاه ساختاربندی می کنند
به دلیل همین سادگی و منطق مشخص، این مدل ها شفافیت بالایی دارند و می توان به راحتی بررسی کرد که مدل در هر مرحله چه تصمیمی و به چه دلیلی گرفته است.
در مقابل، شبکه های عصبی عمیق از ده ها، صدها یا حتی هزاران لایه تشکیل شده اند که هر لایه شامل مجموعه ای از نورون هاست. هر نورون به تنهایی عملیات بسیار ساده ای انجام می دهد، اما ترکیب این نورون ها در لایه های متوالی، ساختاری فوق العاده پیچیده، غیرخطی و انعطاف پذیر به وجود می آورد که قادر است روابط چندبعدی و بسیار پیچیده را یاد بگیرد.
در عمل، لایه های ابتدایی معمولا ویژگی های پایه و ساده (مانند لبه ها و خطوط در تصاویر) را تشخیص می دهند، لایه های میانی الگوهای متوسط (مثل شکل چشم، بینی یا چرخ خودرو) را می سازند و لایه های عمیق تر به درک مفاهیم انتزاعی و کلی (مانند «چهره انسان» یا «گربه») می رسند.
نتیجه این تفاوت ساختاری کاملا روشن است:
مدل های کلاسیک یادگیری ماشینی برای مسائل نسبتا ساده تر، با ابعاد پایین تر و الگوهای قابل بیان با ویژگی های محدود بسیار مناسب اند و شفافیت بالایی دارند. در مقابل، مدل های عمیق در مسائل با ابعاد بسیار بالا، داده های غیرساخت یافته و الگوهای پیچیده (مانند تصویر، ویدئو، صدا و متن های طولانی) به طور چشمگیری برتر عمل می کنند.
علاوه بر این، ساختار لایه لایه ی شبکه های عمیق امکان طراحی معماری های تخصصی مانند شبکه های کانولوشنی (CNN)، شبکه های بازگشتی (RNN)، ترانسفورمرها و … را فراهم می کند؛ انعطافی که در الگوریتم های کلاسیک یادگیری ماشینی وجود ندارد و همین ویژگی، یادگیری عمیق را به انتخاب غالب در پیشرفته ترین کاربردهای هوش مصنوعی امروز تبدیل کرده است.
۲- تفاوت در کاربرد و نوع مسئله
هرچند یادگیری ماشینی و یادگیری عمیق هر دو از خانواده هوش مصنوعی هستند، اما تفاوت های ساختاری شان باعث شده در دنیای واقعی تقریبا به دو مسیر کاملا مجزا تبدیل شوند.
وقتی داده محدود است یا الگوها نسبتا ساده و قابل بیان با ویژگی های مشخص هستند، الگوریتم های کلاسیک یادگیری ماشینی معمولا بهترین و کارآمدترین انتخاب اند. مثال های روزمره و بسیار رایج این دسته عبارتند از:
- پیش بینی ریسک اعتباری و وام
- تحلیل رفتار مشتری بر پایه ی داده های جدولی (مانند CRM)
- پیش بینی احتمال ترک سرویس (Churn Prediction)
- تشخیص تقلب مالی
- امتیازدهی سرنخ های فروش
در این مسائل، داده ها معمولا ساختاریافته اند، تعداد ویژگی ها محدود و معنادار است و الگوریتم های کلاسیک با سرعت بالا و منابع کم می توانند دقت قابل قبولی ارائه دهند. افزایش بی مورد پیچیدگی مدل در این سناریوها نه تنها سودی ندارد، بلکه خطر بیش برازش و هزینه ی محاسباتی غیرضروری را به همراه دارد.
در مقابل، وقتی داده ها از نوع غیرساخت یافته و پیچیده باشند، مانند تصویر، ویدئو، صدا، سری های زمانی طولانی یا متن های طبیعی که یادگیری عمیق به وضوح برتری خود را نشان می دهد. دلیل اصلی این برتری هم آن است که روابط درونی این نوع داده ها چندبعدی، پنهان و به شدت غیرخطی هستند و استخراج دستی ویژگی مناسب تقریبا غیرممکن است. شبکههای عصبی عمیق با ساختار لایه لایهی خود تمام این پیچیدگی را به صورت خودکار جذب می کنند و بدون نیاز به مهندسی ویژگی، الگوهای عمیق و پنهان را کشف و مدل می کنند.
به عنوان مثال، در تشخیص چهره هیچ ویژگی ساده و ثابتی وجود ندارد که بتوان آن را به صورت دستی استخراج کرد؛ بلکه ترکیبی از شکل ها، بافت ها، نسبت ها و روابط فضایی است که تنها یک شبکه عمیق می تواند به صورت سلسله مراتبی آن را یاد بگیرد.
در پردازش زبان طبیعی نیز همین الگو تکرار می شود؛ یعنی مدل های کلاسیک برای متن های کوتاه و ساخت یافته (مثل طبقه بندی اسپم) عملکرد خوبی دارند، اما در وظایف پیچیده تر مانند درک زمینه ی طولانی، خلاصه سازی متون، پاسخ به پرسش های آزاد یا ترجمه ی همزمان، مدل های عمیق (به ویژه بر پایه ی معماری ترانسفورمر) فاصله ی بسیار زیادی با روش های سنتی ایجاد کرده اند.
عامل مهم دیگری که نوع کاربرد را تعیین می کند، نیاز به شفافیت و توضیح پذیری است. مثلا در حوزه های حساس مانند پزشکی، سیستم های مالی، بیمه و تصمیم گیری های قضایی، اغلب قانون یا اخلاق حرفه ای ایجاب می کند که بتوان دلیل دقیق هر پیش بینی را توضیح داد. در این موارد، مدل های کلاسیک به دلیل ساختار ساده و قابل تفسیرشان اولویت دارند. اما در کاربردهایی که دقت و عملکرد نهایی مهم تر از توضیح پذیری است (مانند خودروهای خودران، سیستم های توصیه گر در مقیاس بزرگ یا تشخیص خودکار محتوای تصویری)، یادگیری عمیق انتخاب غالب و گاهی تنها گزینه ی عملی است.
در واقع، هیچ کدام از این دو رویکرد جایگزین کامل دیگری نیست؛ چرا که انتخاب درست همیشه بر اساس ماهیت داده، حجم داده، نیاز به شفافیت، محدودیت های محاسباتی و هدف نهایی پروژه انجام می شود و در بسیاری از سیستم های واقعی امروزی، بهترین نتایج از ترکیب خردمندانه هر دو رویکرد به دست می آید.
۳- تفاوت در میزان داده و توان محاسباتی
حجم دادهی در دسترس و توان محاسباتی موجود، دو خط قرمز واقعی تفاوت بین یادگیری ماشینی کلاسیک و یادگیری عمیق هستند و در عمل اغلب تعیین کنندهترین عامل در انتخاب بین این دو رویکرد به شمار می روند.
الگوریتم های کلاسیک یادگیری ماشینی به طور ذاتی با داده های کم تا متوسط هم کاملا سازگارند؛ تعداد پارامترهای این مدل ها معمولا در حد چند صد تا چند ده هزار است و ساختارشان به گونه ای طراحی شده که حتی با چند صد یا چند هزار نمونه نیز می توانند الگوهای معنادار یاد بگیرند و خروجی قابل اتکایی ارائه دهند.
به همین دلیل، در پروژه های اولیه، استارتاپ ها یا شرکت هایی که هنوز داده ی زیادی جمع آوری نکرده اند، مدل های کلاسیک همچنان انتخاب منطقی و کم ریسک باقی می مانند. حتی وقتی دادهی زیاد هم وجود دارد، اگر ویژگی ها ساده و معنادار باشند، این مدل های سبک همچنان رقابتی و گاهی برتر عمل می کنند.
در مقابل، شبکه های عصبی عمیق برای شکوفایی واقعی به داده ی بسیار حجیم نیاز دارند. مدل های بزرگ امروزی (مانند GPT، BERT، ResNet یا ViT) صدها میلیون تا چند میلیارد پارامتر دارند و برای تنظیم درست این حجم عظیم پارامتر، به ده ها هزار، صدها هزار یا حتی میلیون ها نمونه ی متنوع نیاز است. اگر داده کافی نباشد، مدل به جای یادگیری الگوهای واقعی، صرفا جزئیات تصادفی دادهی آموزشی را حفظ می کند و در مواجهه با داده های جدید به شدت ضعیف عمل می کند (بیش برازش).
از نظر توان محاسباتی نیز فاصله چشمگیری وجود دارد. چرا که آموزش یک مدل کلاسیک (مثل Random Forest یا XGBoost) معمولا روی یک لپ تاپ معمولی یا سرور تک-CPU در چند ثانیه تا چند دقیقه انجام می شود.
اما آموزش یک شبکه عمیق متوسط تا بزرگ تقریبا همیشه به GPU یا TPU قدرتمند و گاهی چندین کارت گرافیک به صورت موازی نیاز دارد و می تواند ساعت ها، روزها یا حتی هفته ها طول بکشد. این موضوع مستقیما هزینهی زیرساخت، مصرف برق و زمان توسعه را بالا می برد و باعث می شود استفاده از یادگیری عمیق تنها زمانی توجیه پذیر باشد که ارزش افزوده ی نهایی آن این هزینه ها را پوشش دهد.
این تفاوت ها فقط به مرحله ی آموزش محدود نمی شود و تا استقرار نهایی سیستم هم ادامه دارد:
- مدل های کلاسیک بسیار سبک هستند و به راحتی روی سرورهای معمولی، دستگاه های لبه ای (Edge Devices) و حتی موبایل اجرا می شوند.
- مدل های عمیق بزرگ معمولا در محیط های محدود منابع کند یا غیرعملی هستند، مگر اینکه از تکنیک های بهینه سازی مانند کوانتیزاسیون، تقطیر دانش یا مدل های کوچک شده استفاده شود.
در کاربردهایی که پردازش بلادرنگ (real-time) حیاتی است (مانند سیستم های تشخیص تقلب لحظه ای، کنترل صنعتی یا دستیارهای صوتی روی گوشی)، سبک بودن و سرعت بالای مدل های کلاسیک اغلب برتری قاطع دارد. اما در پروژه هایی که دقت نهایی و کیفیت نهایی حرف اول را می زند (تشخیص پزشکی از تصویر، خودروهای خودران، تولید محتوا)، سرمایه گذاری روی داده ی بیشتر و سخت افزار قوی تر برای یادگیری عمیق کاملاً منطقی و بازگشت پذیر است.
به همین دلیل، با توجبه به تفاوت یادگیری ماشینی و یادگیری عمیق، تصمیم گیری برای انتخاب، دیگر فقط یک گزینش فنی بر مبنای دقت نیست؛ بلکه یک تصمیم استراتژیک است که باید حجم داده ی موجود، بودجهی سخت افزاری، زمان تحویل پروژه، نیاز به پردازش بلادرنگ و هزینه ی کل چرخه ی عمر سیستم را به طور همزمان در نظر بگیرد. وقتی همه ی این عوامل کنار هم قرار گیرند، انتخاب درست تقریبا خودبه خود مشخص می شود.
انتخاب از میان یادگیری ماشینی و یادگیری عمیق با کمک اکیان

در طول این مقاله به طور کامل دیدیم که یادگیری ماشینی کلاسیک (ML) و یادگیری عمیق (DL) هر کدام در چه موقعیت هایی بهترین عملکرد را دارند:
- ML وقتی داده محدود است، ویژگی ها قابل استخراج هستند و نیاز به شفافیت، سرعت و هزینه ی پایین داریم.
- DL وقتی داده حجیم و غیرساخت یافته است، روابط چندسطحی و پیچیده داریم و دقت نهایی مهم ترین اولویت پروژه است.
با این حال، در دنیای با توجه به تفاوت های یادگیری ماشینی و یادگیری عمیق، انتخاب بین این دو رویکرد همیشه به این سادگی نیست. گاهی مرزها خاکستری می شوند، داده به تدریج رشد می کند یا تیم فنی مطمئن نیست که آیا سرمایه گذاری روی زیرساخت سنگین یادگیری عمیق توجیه پذیر است یا نه. چرا که یک تصمیم اشتباه در این مرحله به راحتی می تواند ماه ها تاخیر، هزینه های غیرضروری و حتی شکست پروژه را به دنبال داشته باشد.
اینجاست که پلتفرم هوش مصنوعی اکیان به کمک شما می آید و انتخاب از میان یادگیری ماشینی و یادگیری عمیق را برایتان ساده می کند. در واقع، اکیان یک محیط یکپارچه و حرفهای است که به شما امکان می دهد به طور همزمان به قوی ترین و به روزترین مدل های هوش مصنوعی دنیا، از جمله GPT، Grok، Claude، Gemini، DeepSeek، LLaMA و ده ها مدل تخصصی دیگر، دسترسی داشته باشید و همهی آن ها را در کنار هم آزمایش کنید.
مدل های پاسخگویی در پلتفرم هوش مصنوعی اکیان:
| پلتفرم / برند | مدلها / زیرمجموعهها |
|---|---|
| OpenAI |
|
|
|
| Anthropic |
|
| X AI |
|
| DeepSeek |
|
| Meta Llama |
|
بنابراین، به جای حدس زدن یا صرف هفته ها زمان برای راه اندازی جداگانه ی مدل های ML و DL، می توانید در چند دقیقه:
- هر دو نوع مدل را روی داده ی واقعی خودتان تست کنید
- دقت، سرعت، مصرف منابع و هزینه ی هر کدام را به صورت شفاف مقایسه کنید
- بهترین گزینه را مستقیماً به پروژه ی خود متصل کنید
این یعنی دیگر نیازی به آزمون و خطای پرهزینه برای انتخاب براساس تفاوت یادگیری ماشینی و یادگیری عمیق نیست؛ چرا که تفاوت عملکرد یادگیری ماشینی و یادگیری عمیق را نه در تئوری، بلکه روی داده ها و مسئله ی واقعی خودتان می بینید و با اطمینان کامل تصمیم می گیرید.
میتوانید همین حالا از اکیان استفاده کنید تا به انواع مدل های هوش مصنوعی دسترسی پیدا کرده و پروژه هایتان با سرعت و دقت بیشتری به نتیجه برسانید. اگر قصد دارید تصمیم های خود را از حدس و گمان به داده و اطمینان تبدیل کنید، اکیان بهترین نقطهی شروع است. با چند کلیک، ثبت نام کرده و خودتان تفاوت یادگیری ماشینی و یادگیری عمیق را احساس کنید: